1The University of British Columbia2Bielefeld University3Linköping University[paper][code][poster]
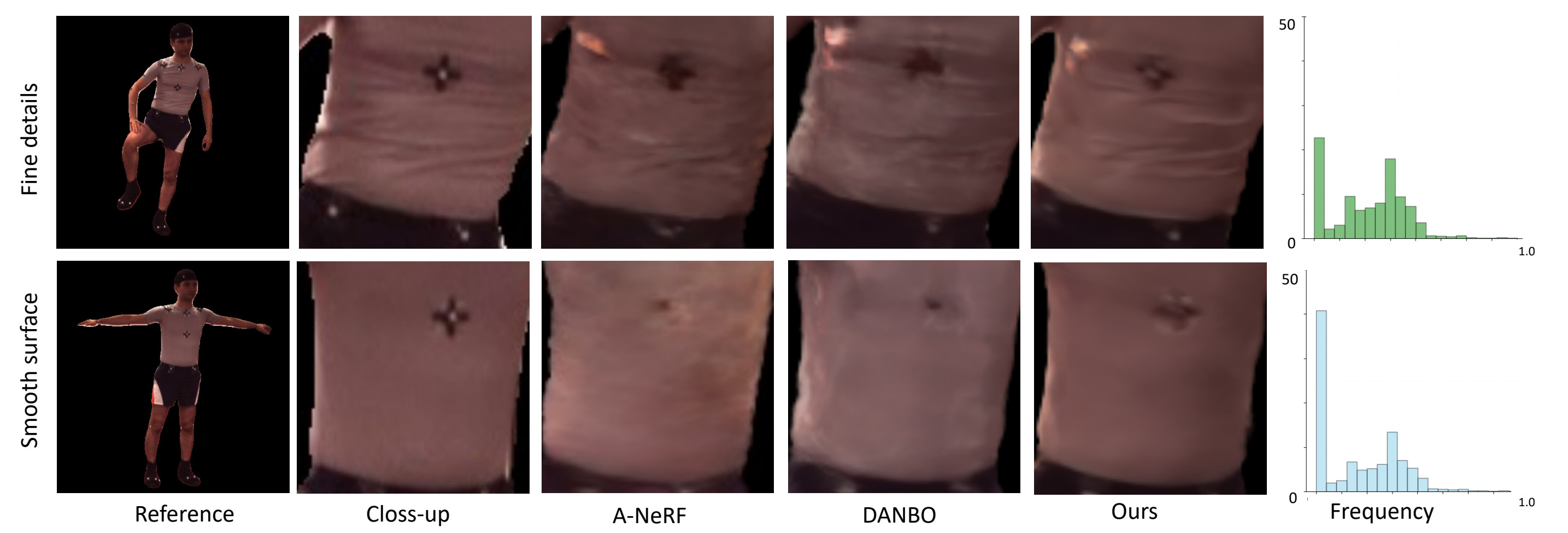
Our frequency modulation approach enables pose-dependent detail by using explicit frequencies that depend on the pose context, varying over frames and across subjects. Our mapping mitigates artifacts in smooth regions as well as synthesizes fine geometric details faithfully, e.g., when wrinkles are present (first row). By contrast, existing surface-free representations struggle either with fine details (e.g. marker) or introduce noise artifacts in uniform regions (e.g. the black clouds, second row). To quantify the difference in frequency of these cases, we calculate the standard deviation (STD) pixels within 5x5 patches of the input closeup and illustrate the frequency histograms of the reference. Even for the same subject in similar pose the frequency distributions are distinct, motivating our pose-dependent frequency formulation.
Abstract
It is now possible to reconstruct dynamic human motion and shape from a sparse set of cameras using Neural Radiance Fields (NeRF) driven by an underlying skeleton. However, a challenge remains to model the deformation of cloth and skin in relation to skeleton pose. Unlike existing avatar models that are learned implicitly or rely on a proxy surface, our approach is motivated by the observation that different poses necessitate unique frequency assignments. Neglecting this distinction yields noisy artifacts in smooth areas or blurs fine-grained texture and shape details in sharp regions. We develop a two-branch neural network that is adaptive and explicit in the frequency domain. The first branch is a graph neural network that models correlations among body parts locally, taking skeleton pose as input. The second branch combines these correlation features to a set of global frequencies and then modulates the feature encoding. Our experiments demonstrate that our network outperforms state-of-the-art methods in terms of preserving details and generalization capabilities.
Architecture
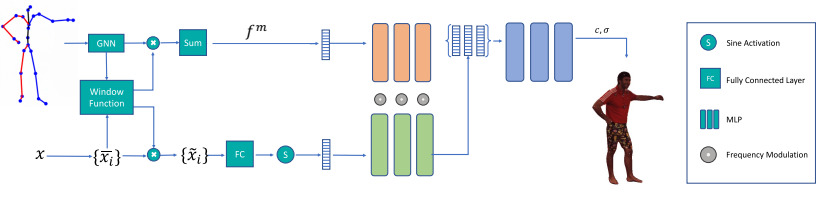
Overall architecture.
First, a graph neural network takes a skeleton pose as input to encode correlations of joints. Together with the relative coordinates x̄i of query point x, a window function is learned to aggregate the features from all parts. Then the aggregated GNN features are used to compute frequency coefficients (orange) which later modulate the feature transformation of point x (green). Finally, density and appearance is predicted as in NeRF.
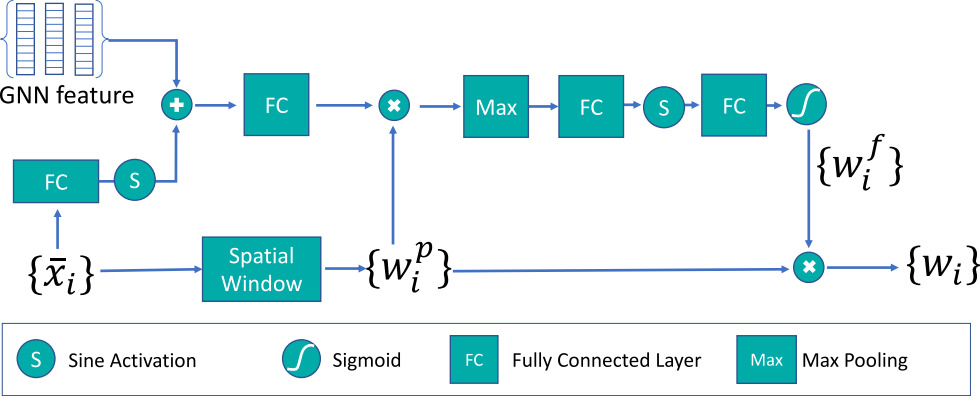
Window function.
The query point location is processed with a spatial and pose-dependent window to remove spurious correlations between distant joints.
Results
Visual comparisons for novel view synthesis.
Compared to baselines, we can vividly reproduce the structured patterns.
Visual comparisons for novel pose rendering.
For novel poses that are unseen during training, cloth wrinkles form chaotically. Hence, none of the methods is expected to match the folds. Ours yields the highest detail, including the highlighted marker texture.
Geometry reconstruction.
Our method yields more precise, less noisy shape estimates. Some noise remains as no template mesh or other surface prior is used.
Video
@inproceedings{
song2024pose,
title={Pose Modulated Avatars from Video},
author={Chunjin Song and Bastian Wandt and Helge Rhodin},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=5t44vPlv9x}
}